
Kaustubh Sridhar
Hi there! I’m a research scientist at Google Deepmind.
I defended my PhD in Electrical and Systems Engineering at the University of Pennsylvania where I was advised by Insup Lee and closely collaborated with Dinesh Jayaraman.
I am interested in creating adaptive generalist agents that are parameter- and sample-efficient, for the digital and physical worlds. Towards this goal, I have worked on generative models and in-context learning, deep reinforcement and imitation learning (particularly from large offline datasets), and robust deep learning.
My recent work on the SIMA agent that can play any 3D virtual world, adding in-context adaptability to pre-trained VLAs, and a retrieval-augmented generalist agent directly aims for this goal.
For the physical world in particular, I believe that world models are the critical breakthrough necessary to transcend this goal and reach embodied AGI. For this reason, my efforts at Google Deepmind are focused on world modeling and robotics.
In the past, I have interned twice at AWS AI Labs and once at Ford and VW’s self-driving unit.
Before starting my PhD, I graduated with honors from the Indian Institute of Technology Bombay.
My CV can be found here.
Work Experience
- May 2025-Present - Google Deepmind
- May-Aug 2023 - Amazon Web Services (AWS) AI Labs
- May-Aug 2022 - Amazon Web Services (AWS) AI Labs
- May-Aug 2021 - Argo AI (Ford and VW’s self-driving partner)
Awards
- Oral Presentation (top 1.8% of 11672 submissions) for REGENT at ICLR 2025
- Best Paper Award Nomination for CODiT at ICCPS 2023
- Top Reviewer (top 10%), NeurIPS 2022
- Outstanding Reviewer (top 10%), ICML 2022
- NSF Travel Grant, ICCPS, 2023
- Student Travel Grant, American Control Conference, 2022
- The Dean’s Fellowship, University of Pennsylvania, 2019
- The Howard Broadwell Fellowship, University of Pennsylvania, 2019
- SN Bose Scholarship, Gov. of India, 2018
- KVPY Fellowship, Gov. of India, 2015
- Dan 1 (black belt), Shotokan Karate Association, 2011
Selected Talks
- I gave an Oral Talk at ICLR 2025 in Singapore on REGENT, our generalist embodied agent. Please find a recording of this talk (including Q&A) at this link.
- I gave talks about training adaptive and sample-efficient generalist embodied agents to different audiences:
- Apr 2025: NTU Singapore
- Nov 2024: Google Deepmind
- Nov 2024: Apple MLR
Media
- SIMA 2 Media Coverage:



Additional Coverage: The RunDown AI, The Decoder, WinBuzzer, SiliconANGLE, Forward Future, The Tech Buzz, Decrypt
- Spotlight On My Research:
![]()
Publications
Please select one of the following topics.
all


Kaustubh Sridhar, Souradeep Dutta, Dinesh Jayaraman, Insup Lee.
- ➥ Conference on Robot Learning (CoRL) 2025 (Acceptance rate 35%).
[PDF] [Code] [Website]

Kaustubh Sridhar, Souradeep Dutta, Dinesh Jayaraman, Insup Lee.
- ➥ International Conference on Learning Representations (ICLR) 2025.
➥ Oral presentation at ICLR 2025, top 1.8% of 11672 submissions.
➥ NeurIPS 2024 workshops on Adaptive Foundation Models and Open World Agents.
[PDF] [Code] [Website]

Kaustubh Sridhar, Souradeep Dutta, Dinesh Jayaraman, James Weimer, Insup Lee.
- ➥ International Conference on Learning Representations (ICLR) 2024 (Acceptance rate 31%).
[PDF] [Code] [Website]
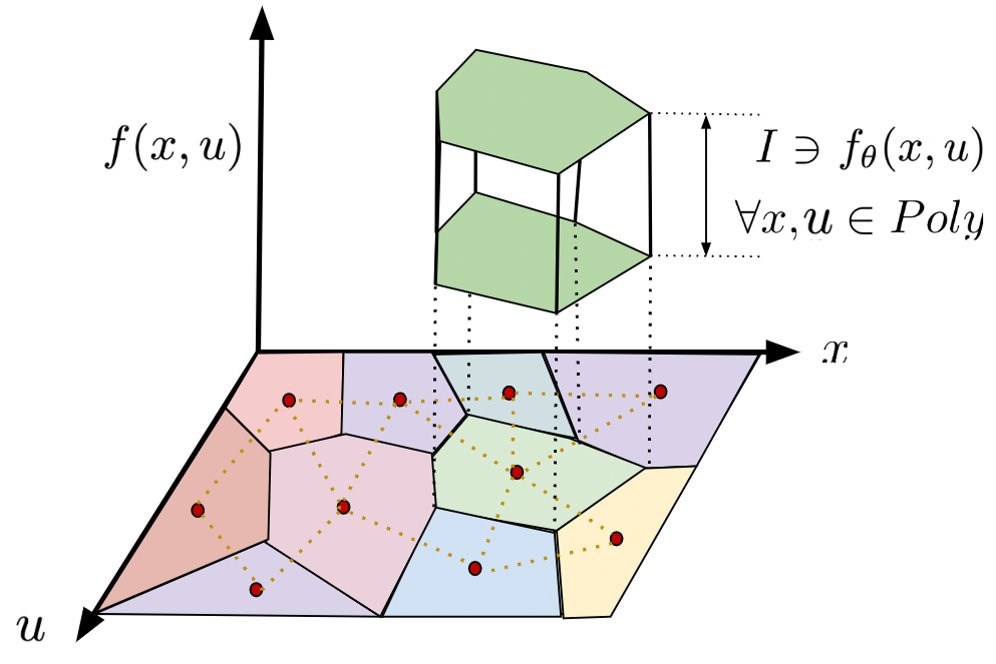
Kaustubh Sridhar, Souradeep Dutta, James Weimer, Insup Lee.
- ➥ ICLR 2023 Workshop on Neurosymbolic Generative Models.
➥ Conference on Learning for Dynamics and Control (L4DC) 2023.
➥ Invited talks at Johns Hopkins University, Amazon Science, and University of Pennsylvania.
[PDF] [Code] [Video] [Poster]

Souradeep Dutta, Kaustubh Sridhar, Osbert Bastani, Edgar Dobriban, James Weimer, Insup Lee, Julia Parish-Morris.
- ➥ Conference on Robot Learning (CoRL) 2022 (Acceptance rate 39%).
[PDF] [Code] [Website] [Poster]

Kaustubh Sridhar, Vikramank Singh, Murali Narayanaswamy, Abishek Sankararaman.
- ➥ arXiv:2212.01348, 2022.
[PDF]

Ramneet Kaur, Kaustubh Sridhar, Sangdon Park, Susmit Jha, Anirban Roy, Oleg Sokolsky, Insup Lee.
- ➥ ICML 2022 Workshop on Principles of Distribution Shift.
➥ ACM/IEEE International Conference on Cyber-Physical Systems (ICCPS) 2023 (Acceptance rate 25.6%).
➥ Best Paper Award Nomination at ICCPS 2023.
[PDF] [Code] [Poster]
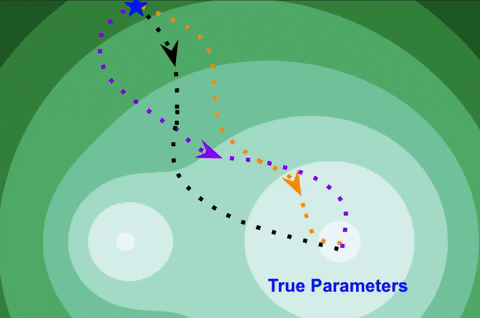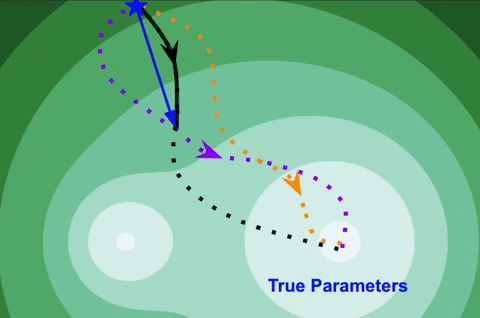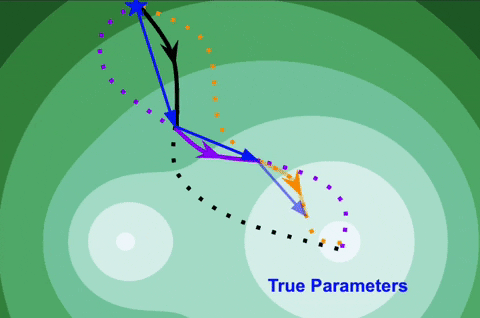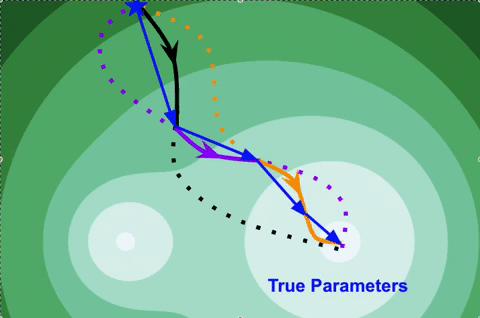
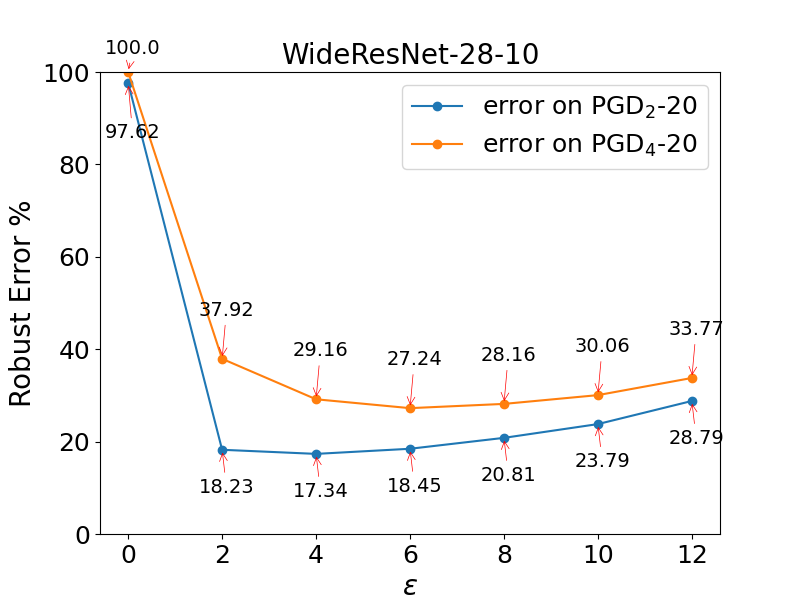
Kaustubh Sridhar, Oleg Sokolsky, Insup Lee, James Weimer.
- ➥ American Control Conference (ACC) 2022.
[PDF] [Code] [Video] [Poster]

Yiannis Kantaros, Taylor Carpenter, Kaustubh Sridhar, Yahan Yang, Insup Lee, James Weimer.
- ➥ ACM/IEEE International Conference on Cyber-Physical Systems (ICCPS) 2021 (Acceptance rate 26%).
[PDF] [Website]
Kaustubh Sridhar, Souradeep Dutta, James Weimer, Insup Lee.
- ➥ arXiv:2206.06496, 2022.
[PDF] [Code]
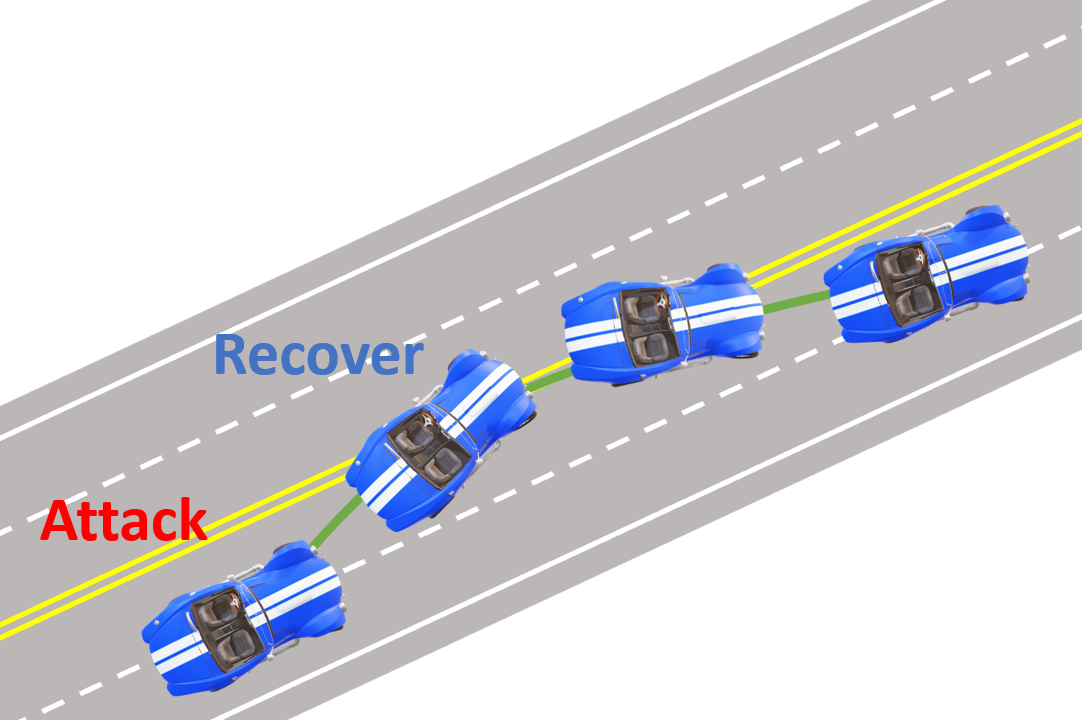
Lin Zhang, Kaustubh Sridhar, Mengyu Liu, Pengyuan Lu, Xin Chen, Fanxin Kong, Oleg Sokolsky, Insup Lee.
- ➥ IEEE Real-Time and Embedded Technology and Applications Symposium (RTAS) 2023.
[PDF] [Code]
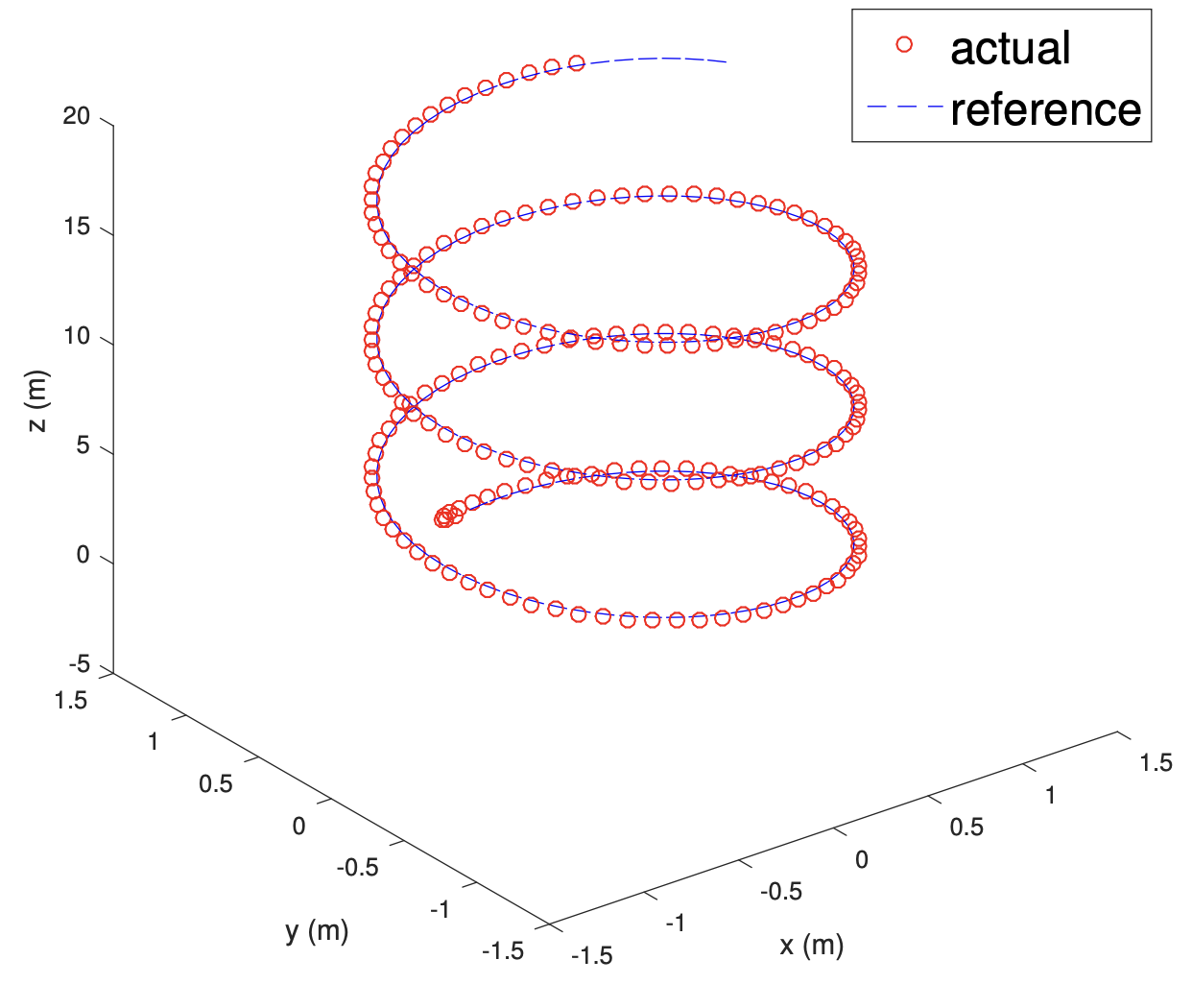
Kaustubh Sridhar, Srikant Sukumar.
- ➥ Conference on Guidance, Navigation, and Contol (EuroGNC) 2019.
[PDF]
other
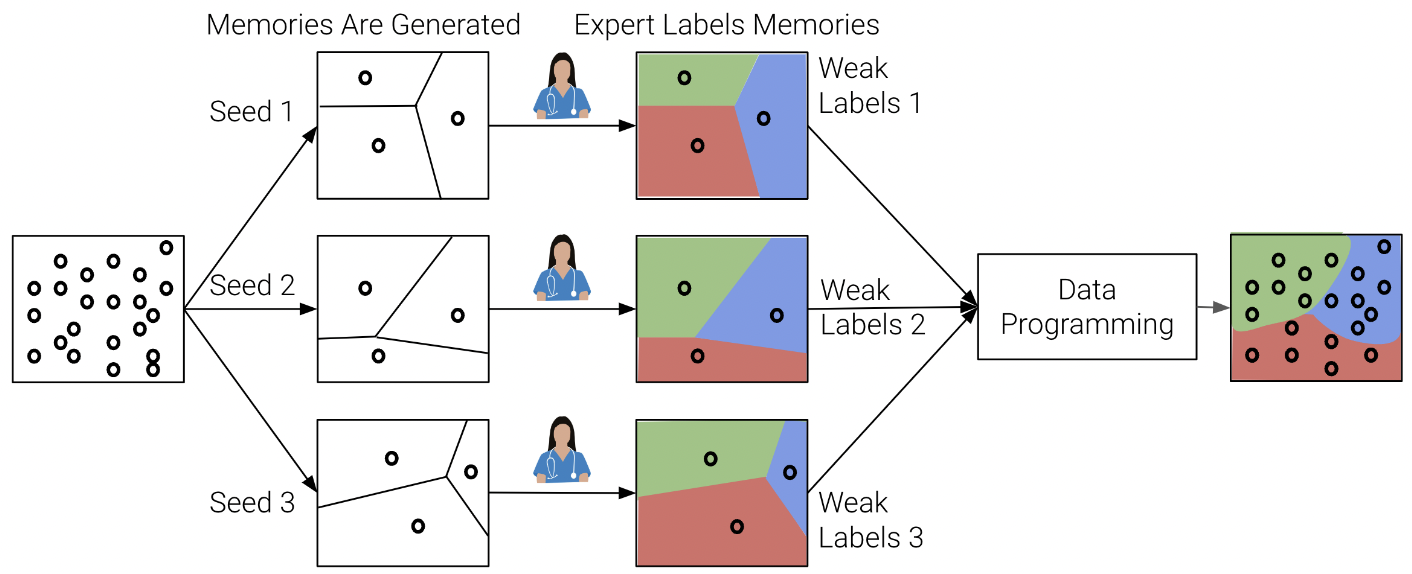
Jean Park, Sydney Pugh, Kaustubh Sridhar, Mengyu Liu, Navish Yarna, Ramneet Kaur, Souradeep Dutta, Elena Bernardis, Oleg Sokolsky, Insup Lee.
- ➥ IEEE/ACM Conference on Connected Health- Applications, Systems and Engineering Technologies (CHASE) 2024
[PDF]
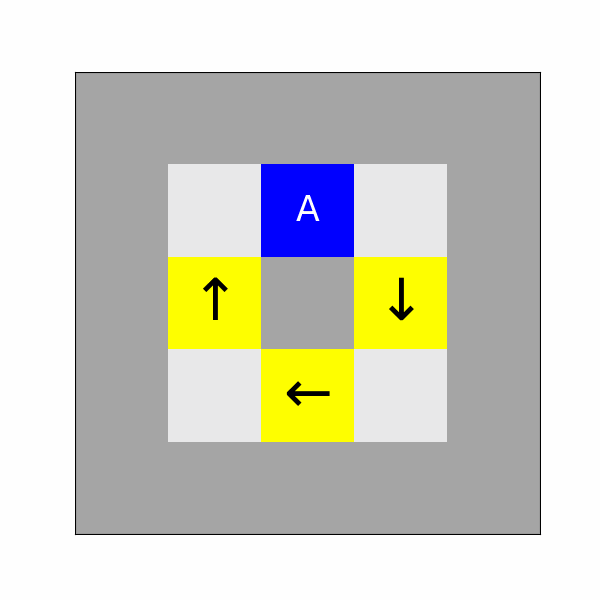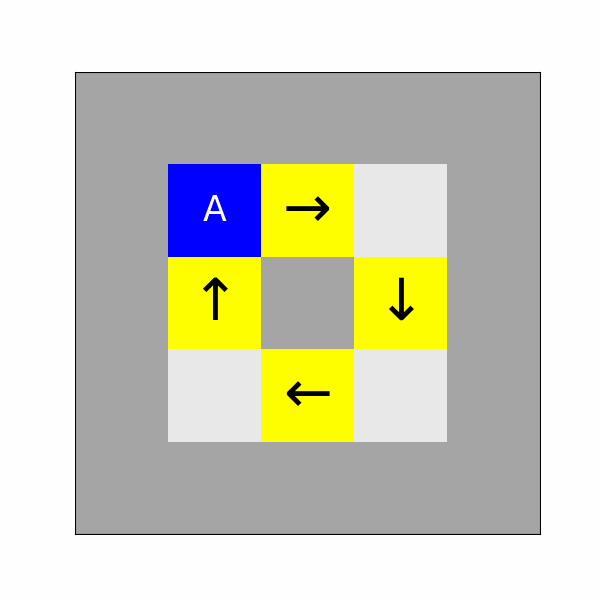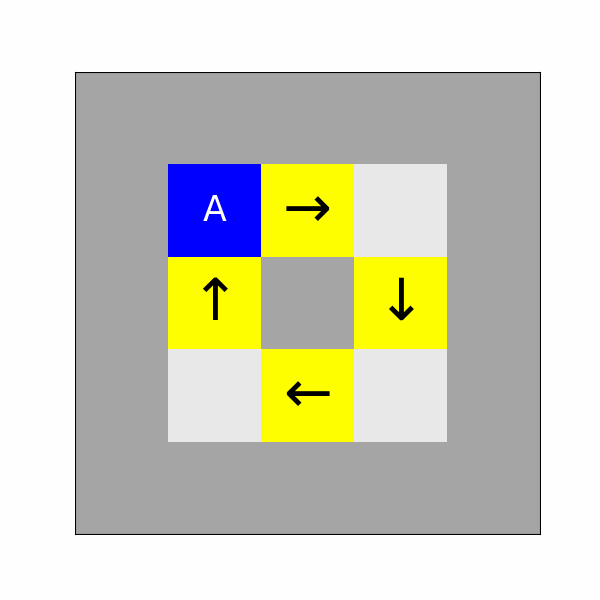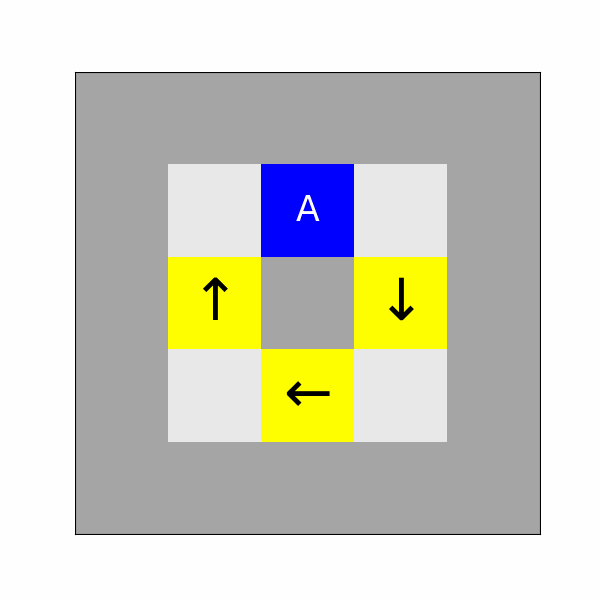
Kaustubh Sridhar, Richard Ren, William Francis, Adam Alavi.
- ➥ Course Project.
[Code]
Lin Zhang, Kaustubh Sridhar, Mengyu Liu, Pengyuan Lu, Xin Chen, Fanxin Kong, Oleg Sokolsky, Insup Lee.
- ➥ IEEE Real-Time and Embedded Technology and Applications Symposium (RTAS) 2023.
[PDF] [Code]
Mengyu Liu, Lin Zhang, Pengyuan Lu, Kaustubh Sridhar, Fanxin Kong, Oleg Sokolsky, Insup Lee.
- ➥ IEEE Real-Time Systems Symposium (RTSS) 2022.
[PDF] [Code]
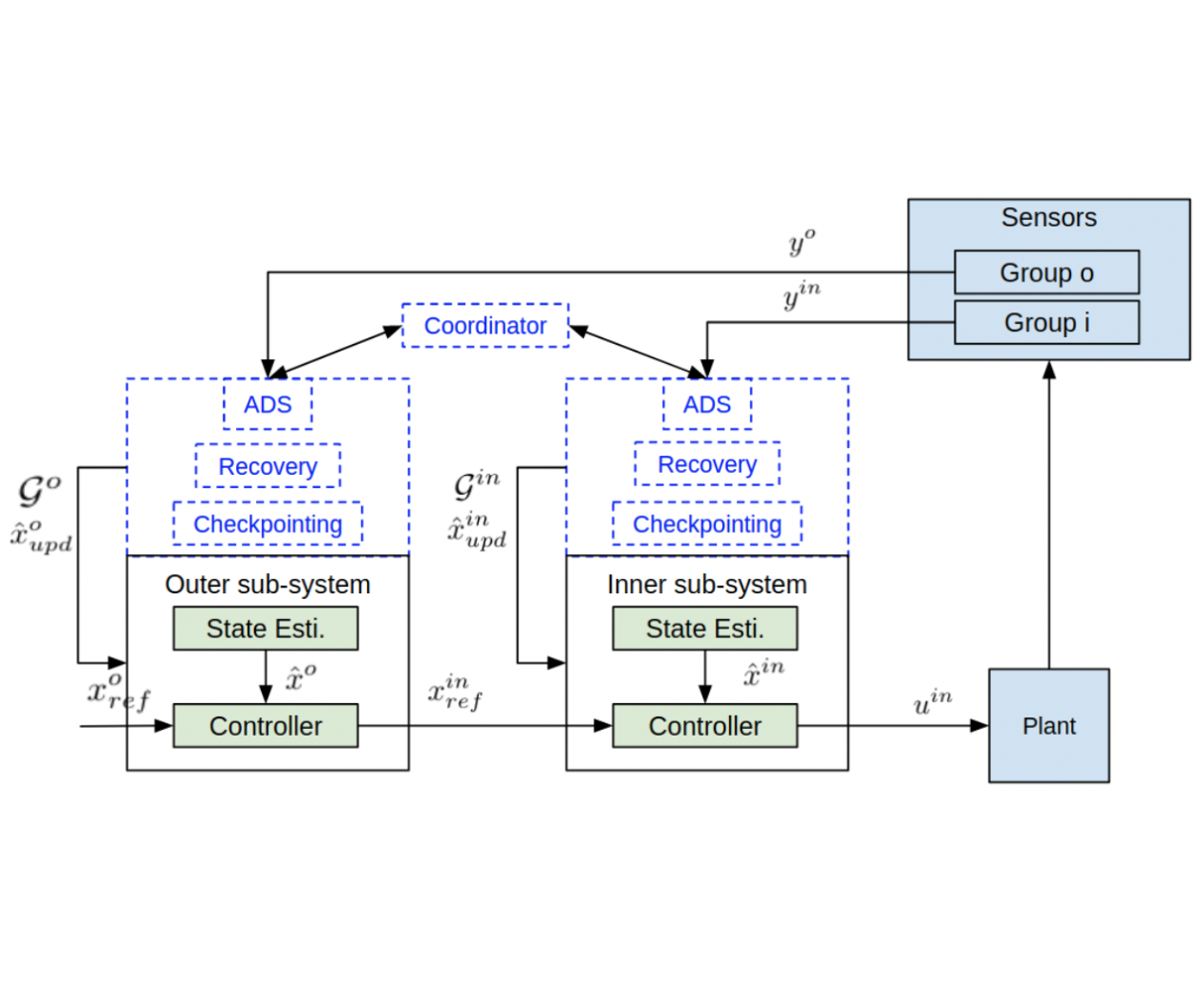
Kaustubh Sridhar, Radoslav Ivanov, Marcio Juliato, Manoj Sastry, Vuk Lesi, Lily Yang, James Weimer, Oleg Sokolsky, Insup Lee.
- ➥ arXiv:2205.08650.
[PDF] [Code]
Kaustubh Sridhar, Srikant Sukumar.
- ➥ Conference on Guidance, Navigation, and Contol (EuroGNC) 2019.
[PDF]
robust deep learning
Ramneet Kaur, Kaustubh Sridhar, Sangdon Park, Susmit Jha, Anirban Roy, Oleg Sokolsky, Insup Lee.
- ➥ ICML 2022 Workshop on Principles of Distribution Shift.
➥ ACM/IEEE International Conference on Cyber-Physical Systems (ICCPS) 2023 (Acceptance rate 25.6%).
➥ Best Paper Award Nomination at ICCPS 2023.
[PDF] [Code] [Poster]
Kaustubh Sridhar, Oleg Sokolsky, Insup Lee, James Weimer.
- ➥ American Control Conference (ACC) 2022.
[PDF] [Code] [Video] [Poster]
Yiannis Kantaros, Taylor Carpenter, Kaustubh Sridhar, Yahan Yang, Insup Lee, James Weimer.
- ➥ ACM/IEEE International Conference on Cyber-Physical Systems (ICCPS) 2021 (Acceptance rate 26%).
[PDF] [Website]
Kaustubh Sridhar, Souradeep Dutta, James Weimer, Insup Lee.
- ➥ arXiv:2206.06496, 2022.
[PDF] [Code]
reinforcement and imitation learning
Kaustubh Sridhar, Souradeep Dutta, Dinesh Jayaraman, Insup Lee.
- ➥ Conference on Robot Learning (CoRL) 2025 (Acceptance rate 35%).
[PDF] [Code] [Website]
Kaustubh Sridhar, Souradeep Dutta, Dinesh Jayaraman, Insup Lee.
- ➥ International Conference on Learning Representations (ICLR) 2025.
➥ Oral presentation at ICLR 2025, top 1.8% of 11672 submissions.
➥ NeurIPS 2024 workshops on Adaptive Foundation Models and Open World Agents.
[PDF] [Code] [Website]
Kaustubh Sridhar, Souradeep Dutta, Dinesh Jayaraman, James Weimer, Insup Lee.
- ➥ International Conference on Learning Representations (ICLR) 2024 (Acceptance rate 31%).
[PDF] [Code] [Website]
Souradeep Dutta, Kaustubh Sridhar, Osbert Bastani, Edgar Dobriban, James Weimer, Insup Lee, Julia Parish-Morris.
- ➥ Conference on Robot Learning (CoRL) 2022 (Acceptance rate 39%).
[PDF] [Code] [Website] [Poster]
Kaustubh Sridhar, Vikramank Singh, Murali Narayanaswamy, Abishek Sankararaman.
- ➥ arXiv:2212.01348, 2022.
[PDF]
generative models
Kaustubh Sridhar, Souradeep Dutta, Dinesh Jayaraman, Insup Lee.
- ➥ Conference on Robot Learning (CoRL) 2025 (Acceptance rate 35%).
[PDF] [Code] [Website]
Kaustubh Sridhar, Souradeep Dutta, Dinesh Jayaraman, Insup Lee.
- ➥ International Conference on Learning Representations (ICLR) 2025.
➥ Oral presentation at ICLR 2025, top 1.8% of 11672 submissions.
➥ NeurIPS 2024 workshops on Adaptive Foundation Models and Open World Agents.
[PDF] [Code] [Website]
Kaustubh Sridhar, Souradeep Dutta, Dinesh Jayaraman, James Weimer, Insup Lee.
- ➥ International Conference on Learning Representations (ICLR) 2024 (Acceptance rate 31%).
[PDF] [Code] [Website]
Kaustubh Sridhar, Souradeep Dutta, James Weimer, Insup Lee.
- ➥ ICLR 2023 Workshop on Neurosymbolic Generative Models.
➥ Conference on Learning for Dynamics and Control (L4DC) 2023.
➥ Invited talks at Johns Hopkins University, Amazon Science, and University of Pennsylvania.
[PDF] [Code] [Video] [Poster]
agents
Kaustubh Sridhar, Souradeep Dutta, Dinesh Jayaraman, Insup Lee.
- ➥ Conference on Robot Learning (CoRL) 2025 (Acceptance rate 35%).
[PDF] [Code] [Website]
Kaustubh Sridhar, Souradeep Dutta, Dinesh Jayaraman, Insup Lee.
- ➥ International Conference on Learning Representations (ICLR) 2025.
➥ Oral presentation at ICLR 2025, top 1.8% of 11672 submissions.
➥ NeurIPS 2024 workshops on Adaptive Foundation Models and Open World Agents.
[PDF] [Code] [Website]

Please find my earlier undergraduate research in motion plannning and control at this link.